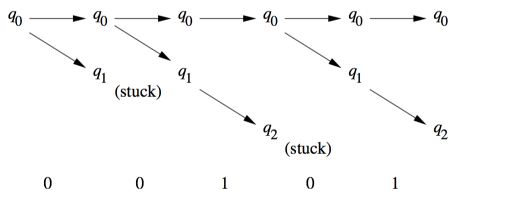
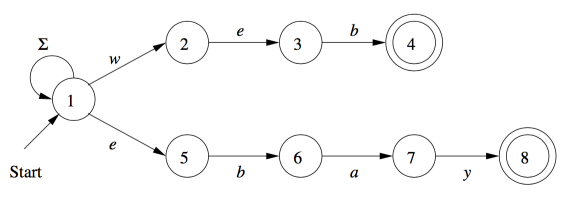
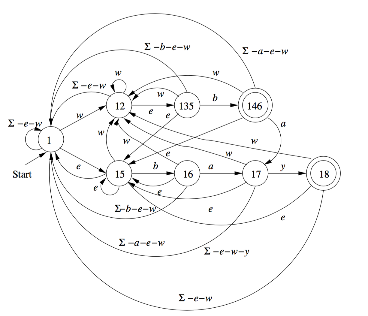
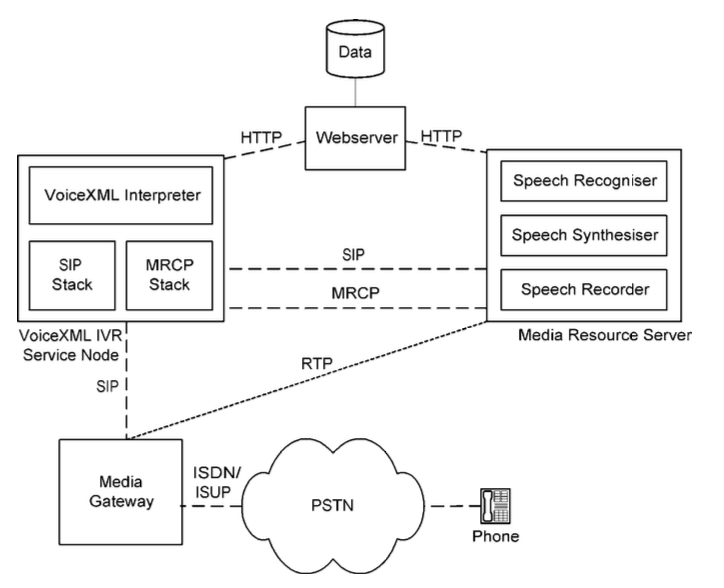
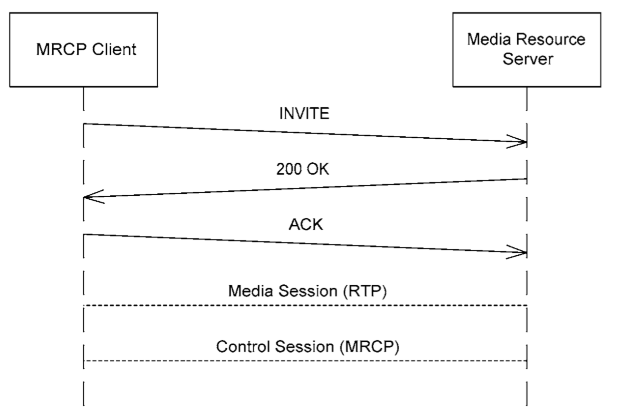
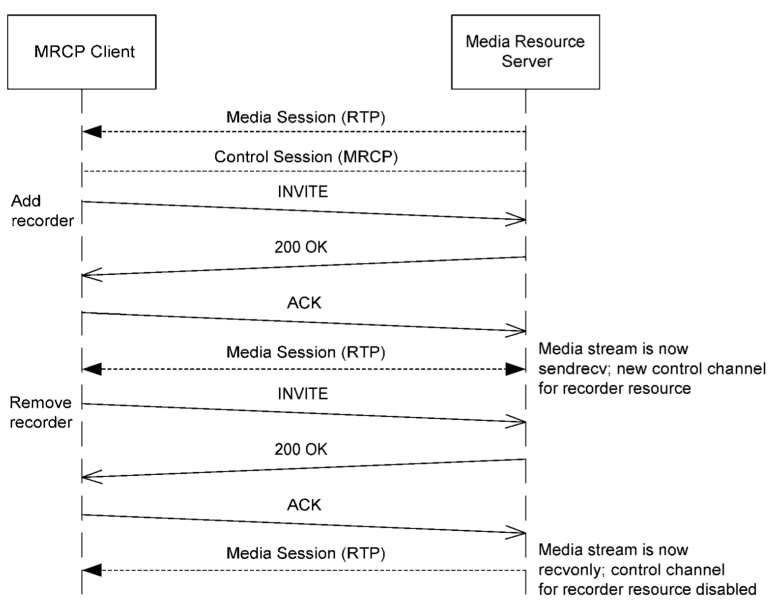
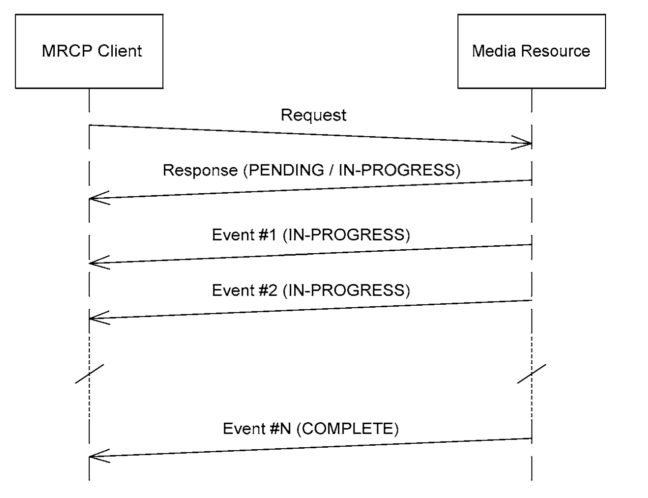
未命名
.red {
color: red;
font-size: 16px;
}
.grey {
color: rgb(138, 143, 138);
}
.mermaid {
background-color: white !important;
}
code {
font-family: "PT Mono", consolas, Menlo, "PingFang SC", "Microsoft YaHei",
monospace;
overflow-wrap: break-word;
word-wrap: break-word;
padding: 2px 4px;
color: #555;
background: #eee;
border-radius: 3px;
font-size: 14px;
}
grey {
color: rgb(138, 143, 138);
}
hi {
font-family: "PT Mono", consolas, Menlo, "PingFang SC", "Microsoft YaHei",
monospace;
overflow-wrap: break-word;
word-wrap: break-word;
padding: 2px 4px;
background: rgb(255, 232, 25);
border-radius: 3px;
font-size: 14px;
}
hi3 {
font-size: 14px;
line-height: 20px;
color: #333;
margin: 200px 0;
font-weight: bold;
}
red {
color: red;
padding: 2px 4px;
}
trs {
font-family: "PT Mono", consolas, Menlo, "PingFang SC", "Microsoft YaHei",
monospace;
overflow-wrap: break-word;
word-wrap: break-word;
/* padding: 2px 4px; */
color: #555;
background: #eee;
border-radius: 3px;
font-size: 14px;
}
empty {
height: 14px;
display: block;
}