1 |
|
这里涉及到逻辑地址(或称虚拟地址)和物理地址的概念。
- 逻辑地址:CPU 所生成的地址。
- 物理地址:内存单元所看到的地址。
用户程序看不到真正的物理地址。用户只生成逻辑地址,且认为进程的地址空间为 0 到 max。物理地址的方位从
fork()会产生一个和父进程完全相同的子进程,但子进程在此后会多 exec 系统调用。出于效率考虑。linux 中引入了写时复制技术,也就是只有进程空间的各段(代码段,数据段,堆栈)的内容要发生变化时,在会将父进程的内容复制一份给子进程。在 fork 之后 exec 之前两个进程用的是相同的物理空间(内存区),子进程的代码段、数据段、堆栈都是执行父进程的物理空间,也就是说,两者的虚拟空间不同,但其对应的物理空间是同一个。当父子进程有更改相应段的行为发生后,再为子进程相应的段分配物理空间。
fork 时子进程获得父进程数据空间,堆和栈的复制,所以变量的地址(虚拟地址)也是一样的,每个进程都有自己的虚拟空间,不同进程的相同的虚拟地址可以对应不同的物理地址。
fork 子进程完全复制父进程的栈空间,也复制了页表,但没有复制物理页面,所以这时虚拟地址相同,物理地址也相同,但是会把父子共享的页面标记为只读,如果父子进程一直对这个页面是同一个页面,直到其中任何一个进程要对共享的页面进行写操作,这时内核会复制一个物理页面给这个进程使用,同时修改页表,而把原来的只读页面标记为可写,留给另外一个进程使用。
内核一般会先调度子进程,很多情况下子进程要马上执行 exec,会情况栈,堆。这些和父进程共享的空间,加载新的代码段,这就避免了写时复制拷贝共享页面的机会。如果父进程先调度很可能写共享页面,会造成写时复制无用。
假定父进程 malloc 的指针指向 0x12345678, fork 后,子进程中的指针也是指向 0x12345678,但是这两个地址都是虚拟内存地址 (virtual memory),经过内存地址转换后所对应的 物理地址是不一样的。所以两个进城中的这两个地址相互之间没有任何关系。
(注 2:但实际上,linux 为了提高 fork 的效率,采用了 copy-on-write 技术,fork 后,这两个虚拟地址实际上指向相同的物理地址(内存页),只有任何一个进程试图修改这个虚拟地址里的内容前,两个虚拟地址才会指向不同的物理地址(新的物理地址的内容从原物理地址中复制得到))
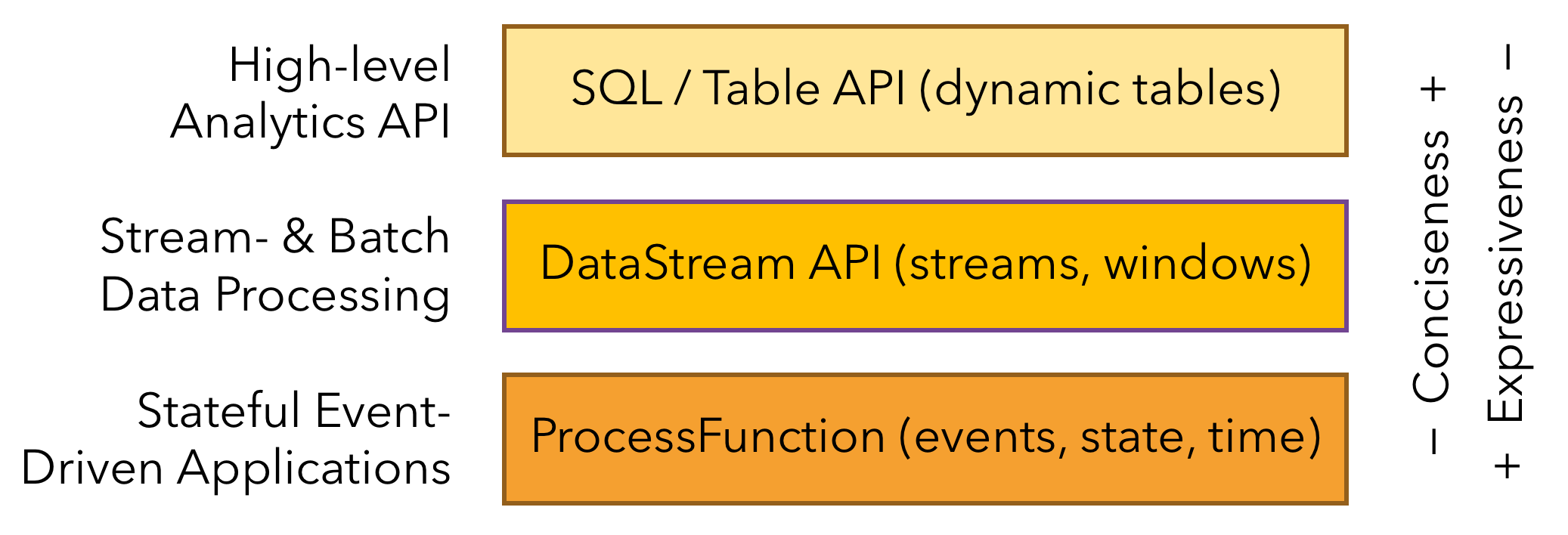
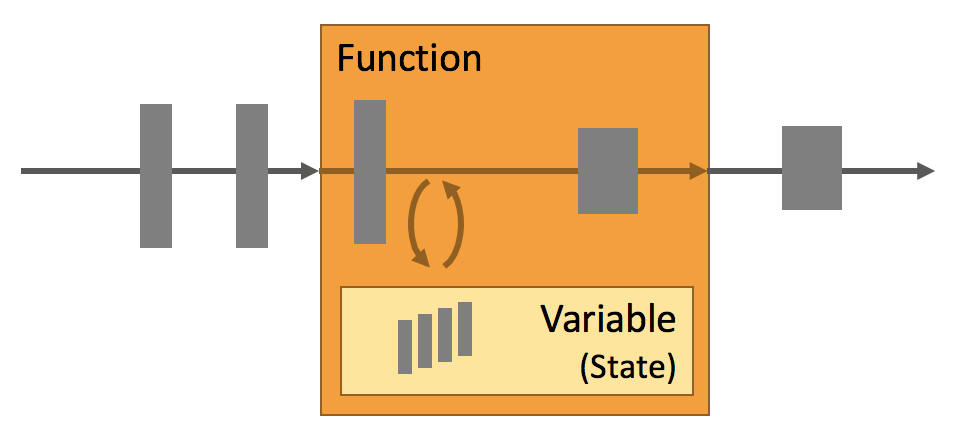 应用状态是 Flink 中的一等公民,FLink 提供了许多状态管理相关的特性,其中包括:
应用状态是 Flink 中的一等公民,FLink 提供了许多状态管理相关的特性,其中包括: