概念
有限状态机简称状态机,状态机表示有限个状态以及在这些状态之间的转移和动作等行为的数学模型。通俗的描述就是状态机定义了一套状态变更的流程:状态机包括一个状态集合,定义当状态机处于某一个状态的时候它所能接收的事件以及可执行的行为,执行完成后状态机所处的状态。状态机包含以下几个重要的元素:
- State:状态。一个标准的状态机最少包括两个状态:初态和终态。初态是状态机初始化后所处的状态,而终态就是状态机结束时所处的状态。其他的状态都是一些流转中停留的状态。
- Event:事件。执行某个操作的触发器或者口令
- Action:行为。状态变更所要执行的具体行为
- Transition:变更。一个状态接收一个事件执行了某些行为到达了一个状态的过程。它表示状态机的运转流程。
应用场景
状态机主要的应用场景就是流程控制。一个状态机定义以后,在某个状态下就只接收固定的 Event,也就是执行指定的操作,这样流程就能按照预期定义的那样流转,不会出现乱入的情况,执行了一些在某个状态下不允许执行的操作。
示例
编写一个程序,以每行一个单词的形式打印其输入
我们使用状态机的思想来解决这个问题
状态集:当前字符在单词内记做 IN,当前字符不在单词内记做 OUT,初态为 OUT 当前状态为 IN 时:若当前字符为空白字符(空格,制表,换行符),则输出换行并改变状态为 OUT,否则输出字符并保持状态为 IN 当前状态为 OUT 时:若当前字符为空白字符(空格,制表,换行符),则保持状态为 OUT,否则输出字符并改变状态为 IN
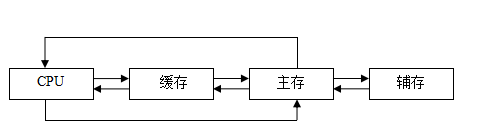 缓存-主存层次主要解决 CPU 和主存速度不匹配的问题
缓存-主存层次主要解决 CPU 和主存速度不匹配的问题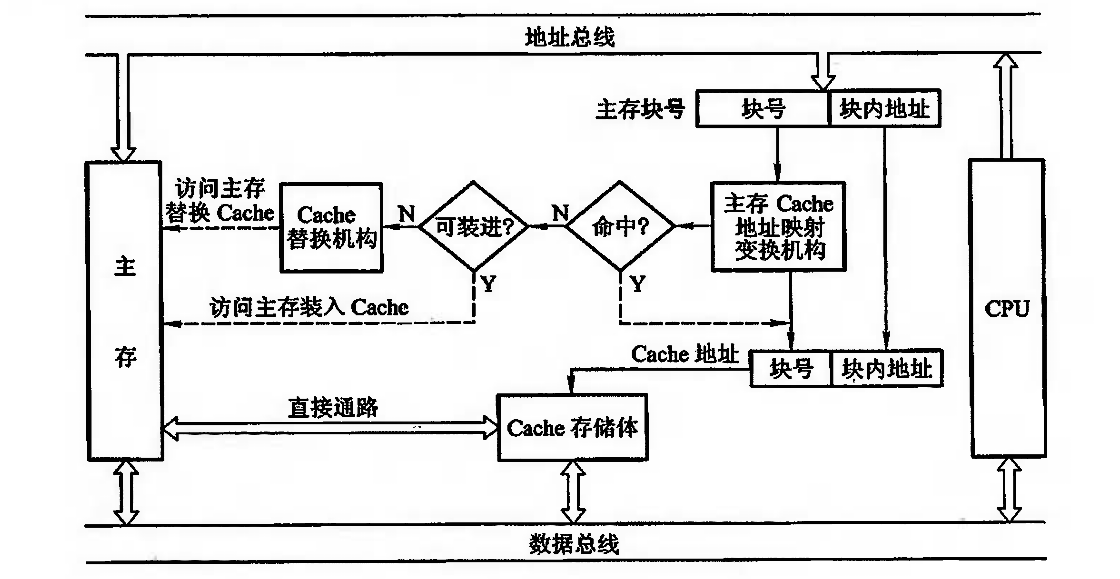


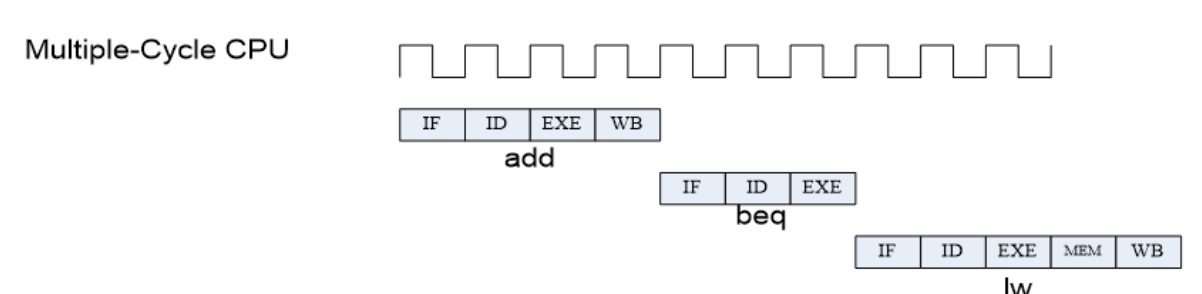
 如图,时钟发生器发出的脉冲信号做出周期变化的最短时间称之为震荡周期,也称为 CPU 时钟周期。它是计算机中最基本的、最小的时间单位。每一次脉冲(即一个震荡周期)到来,芯片内的晶体管就改变一次状态,让整个芯片完成一定任务。一个震荡周期内,晶体管只会改变一次状态。由此,更小的时钟周期就意味着更高的工作频率。 一秒内,震荡周期的个数称为时钟频率,俗称主频。
如图,时钟发生器发出的脉冲信号做出周期变化的最短时间称之为震荡周期,也称为 CPU 时钟周期。它是计算机中最基本的、最小的时间单位。每一次脉冲(即一个震荡周期)到来,芯片内的晶体管就改变一次状态,让整个芯片完成一定任务。一个震荡周期内,晶体管只会改变一次状态。由此,更小的时钟周期就意味着更高的工作频率。 一秒内,震荡周期的个数称为时钟频率,俗称主频。
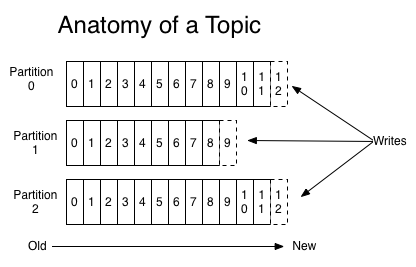
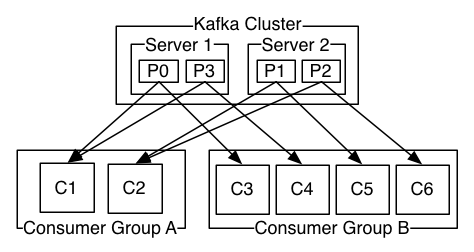
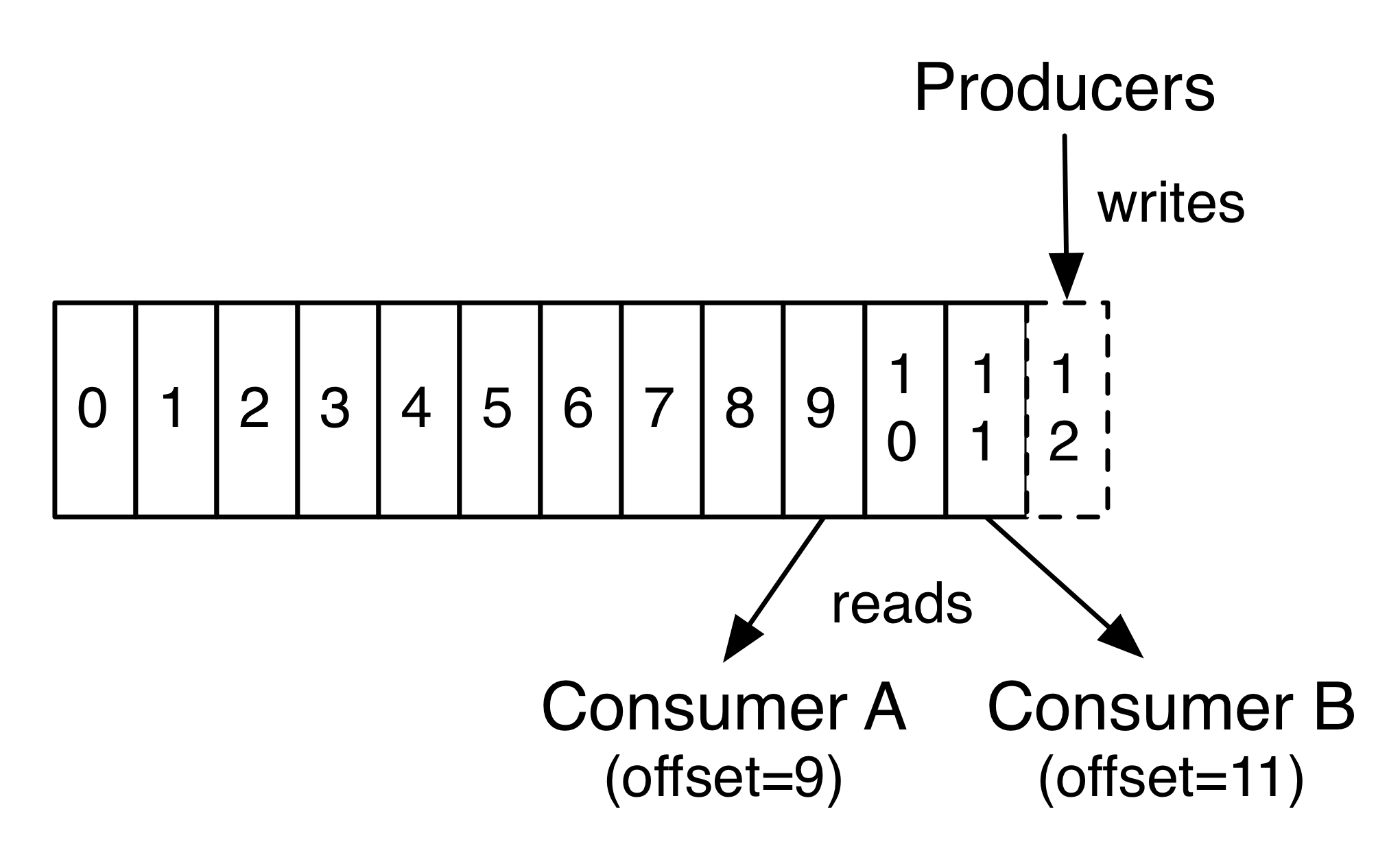 通过操作 offset,我们可以读取还未过期的历史数据,也可以跳过当前数据读取已经写入 kafka 的未来数据
通过操作 offset,我们可以读取还未过期的历史数据,也可以跳过当前数据读取已经写入 kafka 的未来数据