SAXReader
feature属性,禁止校验dtd文件
使用 dom4j 解析 xml
1 | import com.sun.org.apache.xerces.internal.impl.Constants; |
读取String为DOMDocument
1 | String xml = "...xml..."; |
DOMElement
顺序读取文本内容和子元素
1 | DOMElement root = doc.getRootElement(); |
XPATH
dom4j直接获取值
1 | doc.selectObject("substring(/root/name/text(),2)"); |
获取tomcat运行端口
1 | //通过classpath定位tomcat配置文件conf/server.xml,使用xpath去解析 |
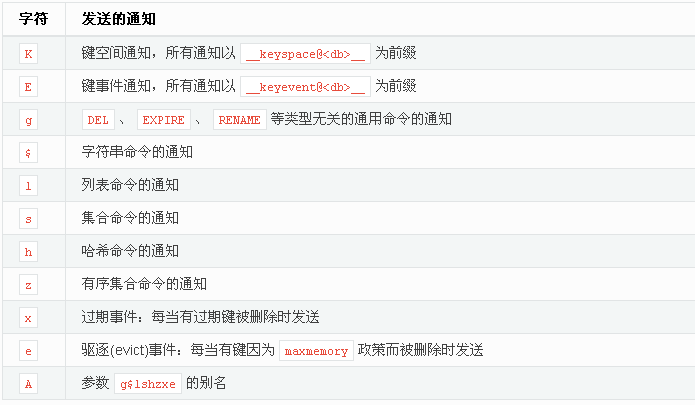 输入的参数中至少要有一个 K 或者 E,否则的话,不管其余的参数是什么,都不会有任何通知被分发。(大小写不敏感)
输入的参数中至少要有一个 K 或者 E,否则的话,不管其余的参数是什么,都不会有任何通知被分发。(大小写不敏感)