端口
redis 节点通常占用两个端口,一个服务端口,一个数据端口,服务端口默认为6379,数据端口则为服务端口+10000,确保这两个端口的防火墙为打开状态。
启动集群
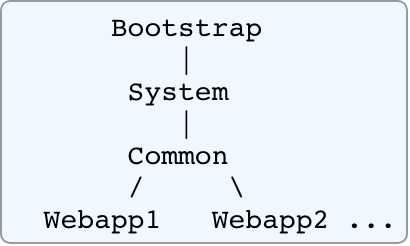
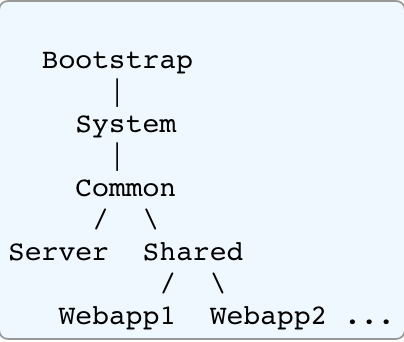
建立多个节点的配置文件目录
1
2
3mkdir cluster-test
cd cluster-test
mkdir 7000 7001 7002 7003 7004 7005每个节点目录下新增
redis.conf配置文件,以下为7000节点最小配置1
2
3
4
5
6port 7000
cluster-enabled yes
cluster-config-file nodes-7000.conf
cluster-node-timeout 5000
appendonly yes
daemonize yes在 cluster-test 目录编写启动脚本
1
2
3
4
5
6
7!/bin/bash
/usr/bin/redis-server 7000/redis.conf
/usr/bin/redis-server 7001/redis.conf
/usr/bin/redis-server 7002/redis.conf
/usr/bin/redis-server 7003/redis.conf
/usr/bin/redis-server 7004/redis.conf
/usr/bin/redis-server 7005/redis.conf启动后我们可以通过
ps -ef|grep redis看到所有 redis 节点都启动了对于使用了
redis 5以上版本,可以使用如下命令来分配hash槽1
2--cluster-replicas 1 使用一个节点作为从节点,那么这里至少需要6个节点,若不指定cluster-replicas则可以只使用三个节点
redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 --cluster-replicas 1执行后可以得到输出
[OK] All 16384 slots covered
同时可以看到各个节点的相关运行时配置文件
node.conf我们有 3 个节点的 7000 端口的node.conf文件,我们可以看到hash槽的分布1
2
3
473a213f442c0299596d464a1b00b26c0eb433a63 127.0.0.1:7002@17002 master - 0 1589883608796 3 connected 10923-16383
3c0f18ab3bcafd94486aab2264833d1a583a0b18 127.0.0.1:7001@17001 master - 0 1589883609703 2 connected 5461-10922
1ebfb6ca239c3780fd76f599c0caace80391806b 127.0.0.1:7000@17000 myself,master - 0 0 1 connected 0-5460
vars currentEpoch 3 lastVoteEpoch 0redis.conf配置bind ip,可以限定不能使用127.0.0.1去访问
分区
是指将将数据分别存储在不同 redis 节点,每个节点仅存储所有 key 的一部分。
优势
- 可存储大量数据,不受单台服务器的物理内存限制
- 分流
缺点
- 涉及多个 key 的操作,若 key 在不同的节点上,则无法执行
- 分区是基于 key 的,若一个 key 中大量数据,它是无法分配到不同的节点
- 分区处理数据相对比较复杂,特别是处理 RDB/AOF 文件时
- 调整容量比较复杂,容量调整时需要实时平衡各个节点的数据
- 为了保证 redis 执行效率,redis 各个节点的数据使用异步的方式同步数据,因此 redis 不保证强一致性。若需要确保某个
key的数据等待同步完返回,则可使用wait指令
分区方式
redis 使用 hash 函数将 key 转换为一个数字,然后根据节点数量进行模运算,根据余数将其分配到指定的节点。
- hash 分配具有一致性,即同一个 key 计算出的 hash 值是固定的
- 客户端分区 有调用端选择正确的节点读写数据
- 代理服务分区 使用一个中间服务器,来转发请求
- 请求路由 随机请求一个服务器,由服务器确认数据在哪个节点,当数据请求到错误的节点时,自动转发请求到正确的节点
redis 通过计算 key 的hash槽来将数据分配到指定的节点,每个节点占据固定长度的hash槽,这个就方便新增或者删除节点
1 | 查看hash槽在节点上的分布 |
hash tag
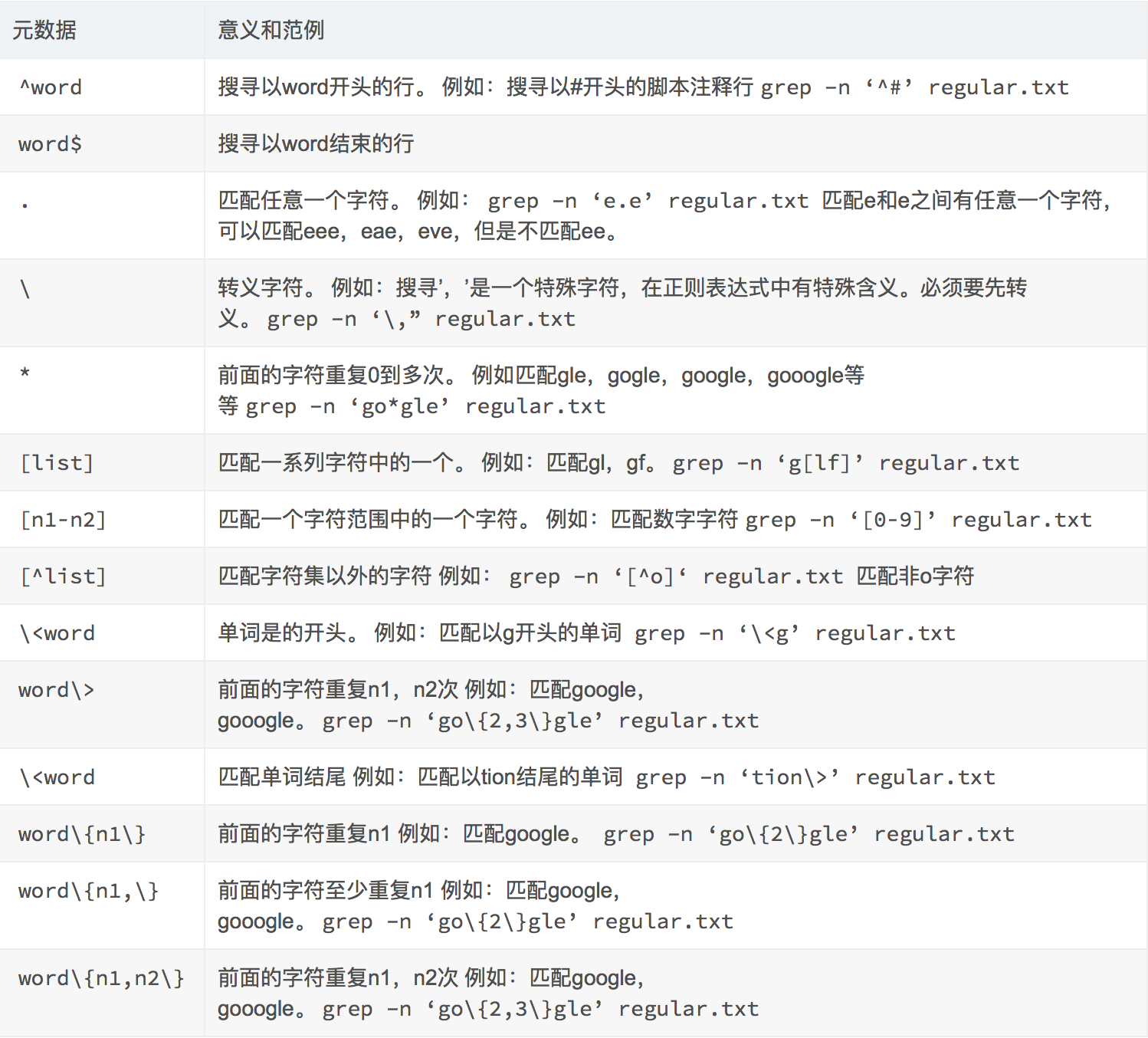
当我们希望一些 key 分配到同一个节点时,我们可以使用hash tag,redis 仅会对 key 中的hash tag进行 hash 函数运算,hash tag是指第一个'{'到第一个'}'之间,不考虑嵌套关系,若第一个'{'和第一个'}'之间为空,则放弃hash tag 例如
{user}100 -> user {user}{100}1 -> user {user{}10}0 -> user{ {}{user}100 -> {}{user}100
重分配
当需要新增或者移除节点时,redis 需要将 key 重新进行分配到剩余节点上。